 伊藤忠テクノソリューションズの科学・工学系情報サイト
伊藤忠テクノソリューションズの科学・工学系情報サイト

コラム:超音波・電磁技術
科学エンジニアリング第2部 応用技術課 猿橋 正之
[2022/06/30]
超音波解析ソフトウェアComWAVEの最新バージョン(Ver.12)が5月にリリースされました。今回追加された機能の中から、共有メモリ型GPUソルバー(Unified Memory版)とその実行環境について紹介いたします。
ComWAVEではGPUによる高速化にも力を入れており、GPUソルバーの提供は比較的早い、今から10年前の2012年にVer.5にて対応がなされました。当時のHPC目的のGPUボードのメモリサイズは数GB程度でありComWAVEで計算可能な要素数は5000万要素程度に限られたものでしたが、マルチGPU計算対応になり計算可能な要素数がGPUの数に比例して増えると数億要素の問題も取り扱えるようになり解析モデルの適用範囲が広がりました。その後、年を追うごとに、GPUは計算速度の向上、搭載メモリの増加がなされ、今ではCPUメインメモリと遜色ないサイズの80GBのメモリを搭載したGPUも登場しています。このようなGPUアーキテクチャ、関連ライブラリの進歩には目を見張るものがあり、HPC分野だけではなくAI・深層学習の分野にもGPUの活用範囲が広がっているのはご存知の通りかと思います。
2012年当時は計算目的でGPUを利用するお客様はまだ少なく、ComWAVEでのGPUソルバーの提供はオプション扱いでしたが、近年シミュレーションにおけるGPU利用が身近になってきていることもあり、GPUをComWAVEの標準機能として使えるようにする切り替え作業を現在進めております。また、従来のGPUソルバーは対象とするデータがGPUの全メモリに収まらないといけない制限がありましたが、今回追加された共有メモリ型GPUソルバーではGPUのメモリサイズを超えた計算が可能になります。これは、GPUのメモリが足りない場合にCPUのメインメモリを使うというものであり、計算速度はGPUの全メモリに収まる場合ほどではないものの、CPU単体に比べて高速に計算できGPUの恩恵を受けられるものになっています(対応GPUのアーキテクチャとしてはPascal世代以降のものである必要があります)。
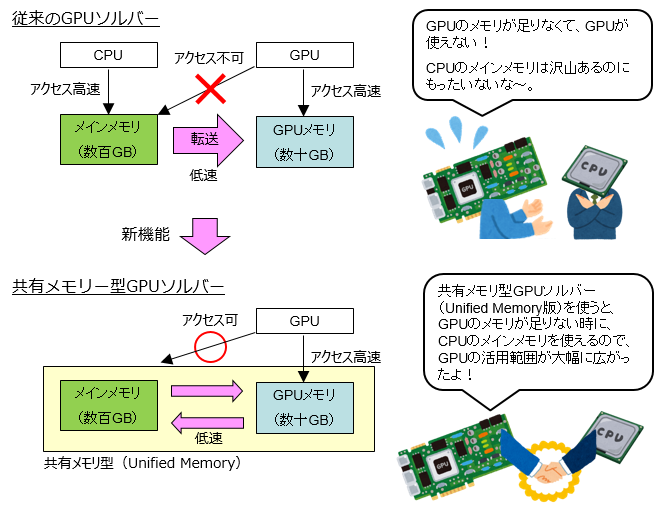
共有メモリー型GPUソルバー
試しに、3.5億要素の均一材料モデル(メモリ約25GB使用)について、NVIDIA Tesla V100(GPUメモリ16GB)を使用して計算したところ、CPU単体と比較して10~15倍の高速化を確認できました。全データが収まるサイズのGPUを使用した場合は20~40倍の高速化であったことから本来の半分程度の高速化にはなりますが、GPUの恩恵を受けていることが分かります。
このように身近になってきたGPUですが、実行環境としてこのようなGPUを搭載したマシンのご提案・ご提供のサービスも行っております。手元のマシンで計算実行する、いわゆるオンプレミス環境をご希望の場合、ComWAVEで解決したい課題についてお聞かせいただき、必要なマシンリソース、推奨マシン構成についてのご提案をさせていただいております。また、オンプレミス環境を用意するまでの時間・コストを削減したい、スポット的に利用したい場合は、クラウド環境をご利用いただくことも可能です。特にオンプレ環境では計算がなかなか難しい100億要素超の大規模解析[1]や、AI学習の教師用データとしてシミュレーションデータを数多く用意したい場合などには、実行環境を柔軟に用意できるクラウド環境が有効です。現在、クラウドとしてRescaleを利用したサービス(ComWAVEクラウド)を提供していますが、プライベートクラウドなどその他のクラウド対応への要望につきましては別途ご相談ください。
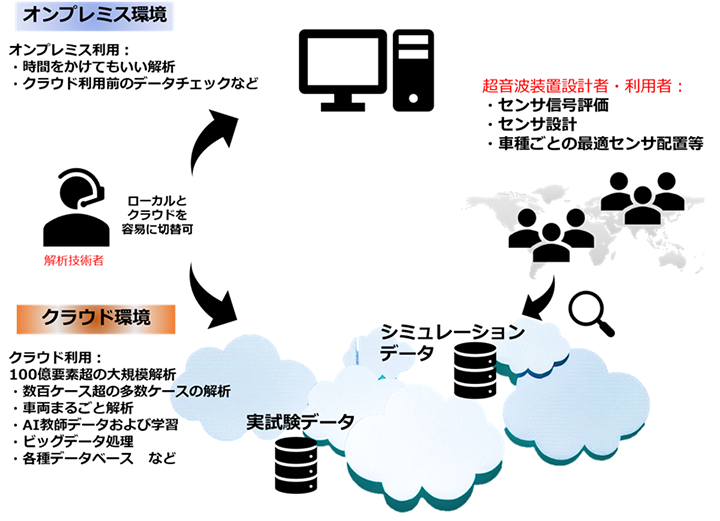
図2 オンプレミス環境とクラウド環境
超音波解析ソフトウェア ComWAVE
https://www.eng-eye.com/ComWAVE/

